
PEEK: Picking Essential frames as Efficient Knowledge distillation
Abstract
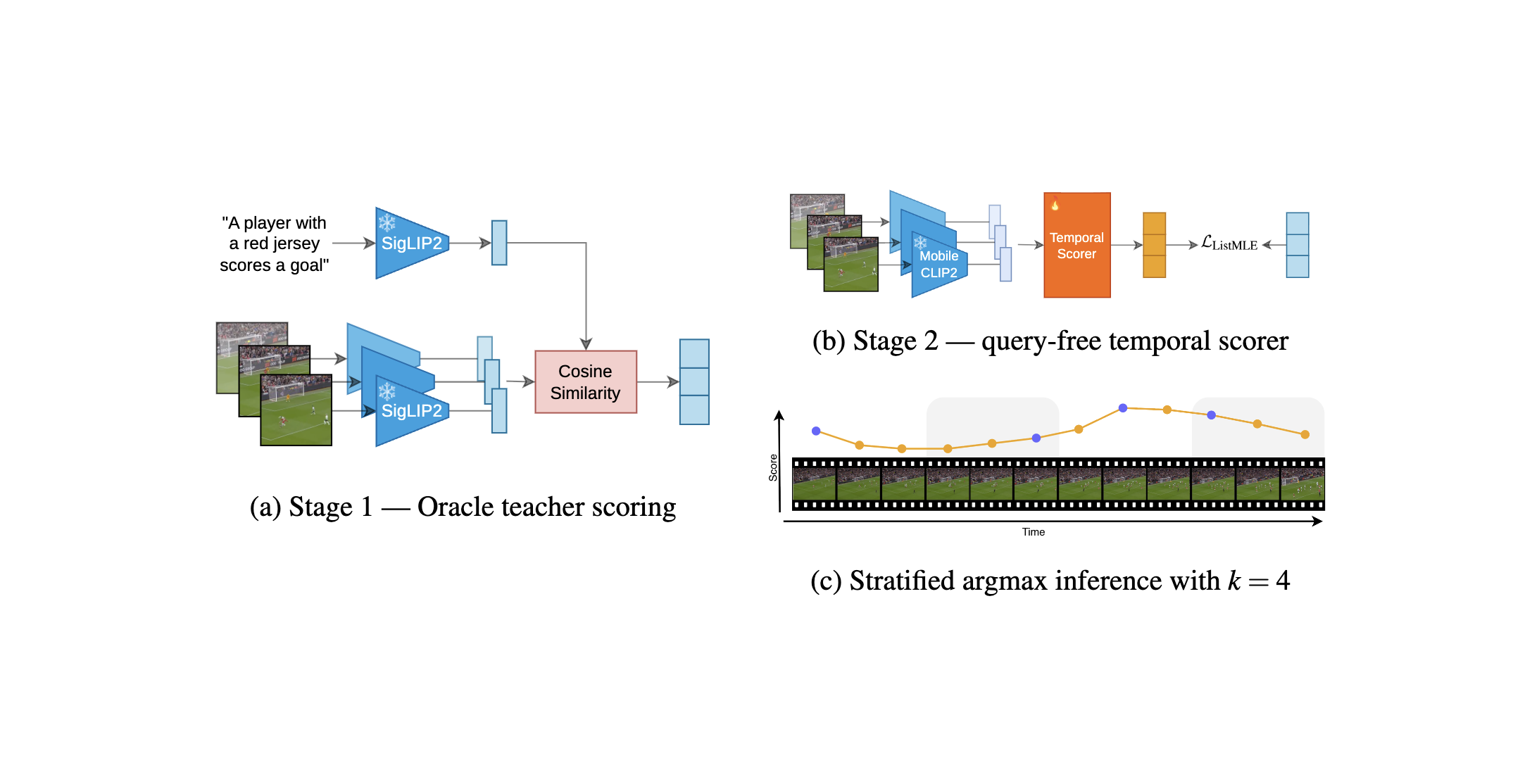
Video-language models can process only a limited number of frames, making frame selection a key bottleneck for efficient video captioning. Most captioning pipelines still rely on uniform sampling, which is computationally cheap but agnostic to visual content. Adaptive frame sampling has recently emerged as a promising approach for selecting the most informative frames from a video; however, existing methods remain computationally expensive. We introduce PEEK, an efficient dynamic frame sampling method that distills caption-conditioned frame relevance rankings from a stronger teacher model into a lightweight temporal model that operates only on visual content.
We find that, overall, on ActivityNet Captions and MSR-VTT, our method outperforms state-of-the-art methods across all evaluated downstream vision language models, especially when only one or two frames are selected for captioning, obtaining the best CIDEr for most frame budgets. On ActivityNet Captions, PEEK is particularly strong, winning 14 out of 16 configurations. Zero-shot evaluation on MSR-VTT shows that our model transfers best at low frame budgets, while results at four and eight frames are more mixed as temporal coverage and visual diversity become increasingly competitive. Compared with recent adaptive baselines, PEEK is both more accurate in the low-budget regime and more efficient: it adds only 5.2% to the captioning time, compared with 65.4% for CSTA and 211.9% for MaxInfo.






