
Meet PEEK: A Tiny Model for Smarter Frame Selection
Get an overview of PEEK: a tiny model for smarter frame selection

![]()
![]()
![]()
![]()
![]()
![]()
Introduction
Vision-language models (VLMs) have made strong progress on image-language tasks, but video understanding remains expensive because videos are long, redundant, and often require sparse relevant cues to be extracted from a frame sequence.
For example, even a short video of 30 seconds is made of 720 images (24 frames per second), and feeding every single image to a captioning model would be too computationally expensive, and for longer videos it becomes untractable.
Before processing a video, most videoLLMs use a simple strategy to process fewer frames: they select a few of them uniformly from the video (e.g. a maximum of 768 regardless of the video length), and hope they will not miss an important event. Uniform sampling is deterministic, model-free, and often produces good results, outperforming adaptive strategies on some benchmarks. This makes uniform sampling a good baseline rather than a naive approach. However, it is still fundamentally content-blind: a short clip where the key event happens in a single instant and a clip where useful evidence is spread across the whole duration are treated identically.
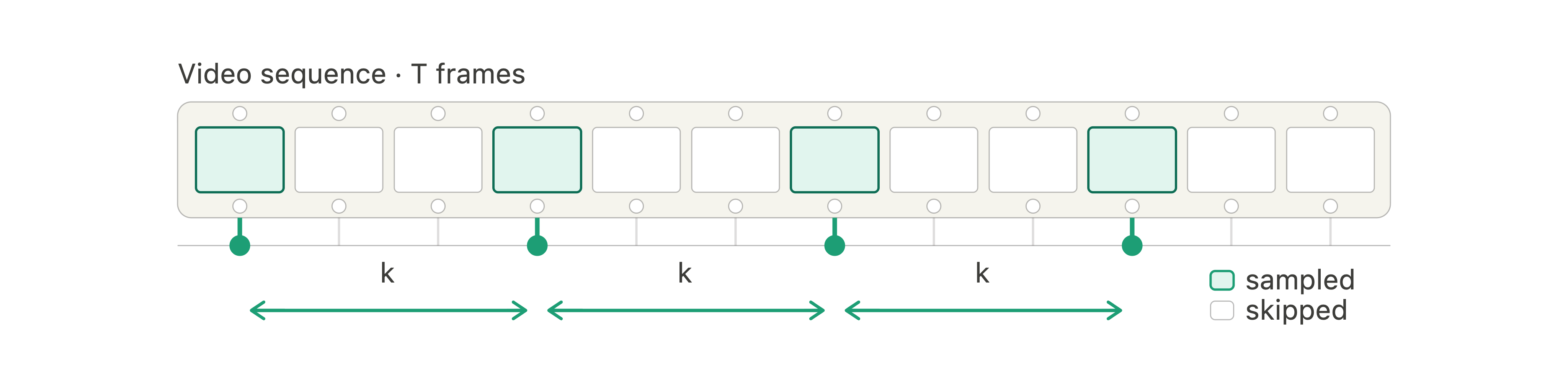
To address this, we propose PEEK, a tiny model that can score each frame in a video, enabling the selection of a few high-score frames only, which are more relevant than selecting them uniformly.
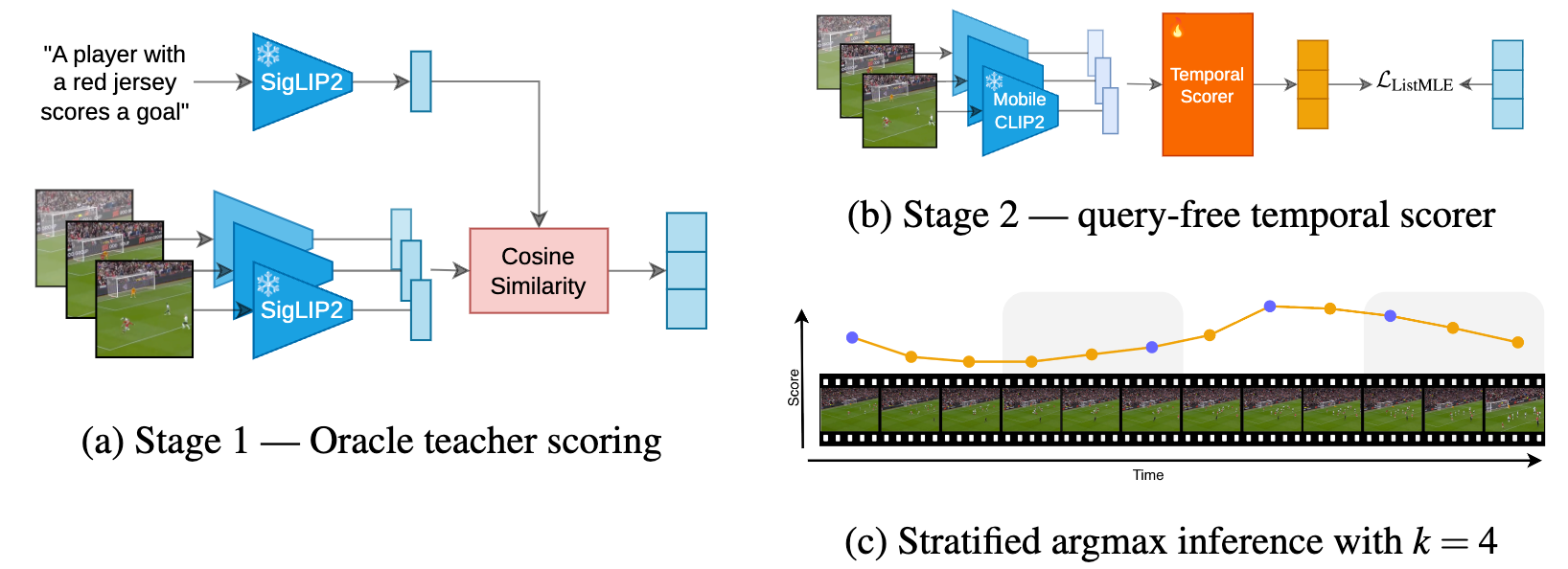
Method
Our method is based on teacher-student knowledge distillation: train a small model (student) to reproduce the outputs of a larger one (teacher).
We use SigLIP2 (400M parameters) as our teacher, acting as an Oracle: for each video-caption pair in our training data the student encodes the caption with its text encoder, and encodes each frame independently with its vision encoder. Then, we compute a similarity score for each frame embedding against the caption embedding, to obtain the final scores the student will learn to reproduce.
Our student is a tiny model (13.1M parameters) that can only see the frames of the video, and is trained to predict a score for each frame, without access to the caption, which we do not have at inference time since our goal is to select relevant frames for video captioning. We use a ListMLE loss function for the student model to learn to rank frames as the teacher. Figure 2 summarizes our approach visually.
At inference time, PEEK can predict a score for each frame in the input video. Since video frames can be very redundant around a frame, selecting directly the frames with the highest scores would result in a high concentration around a few temporal points. To ensure good temporal coverage, we split the input video into several equal temporal windows, and sample the highest-scoring frame from each window, as shown in Figure 3.
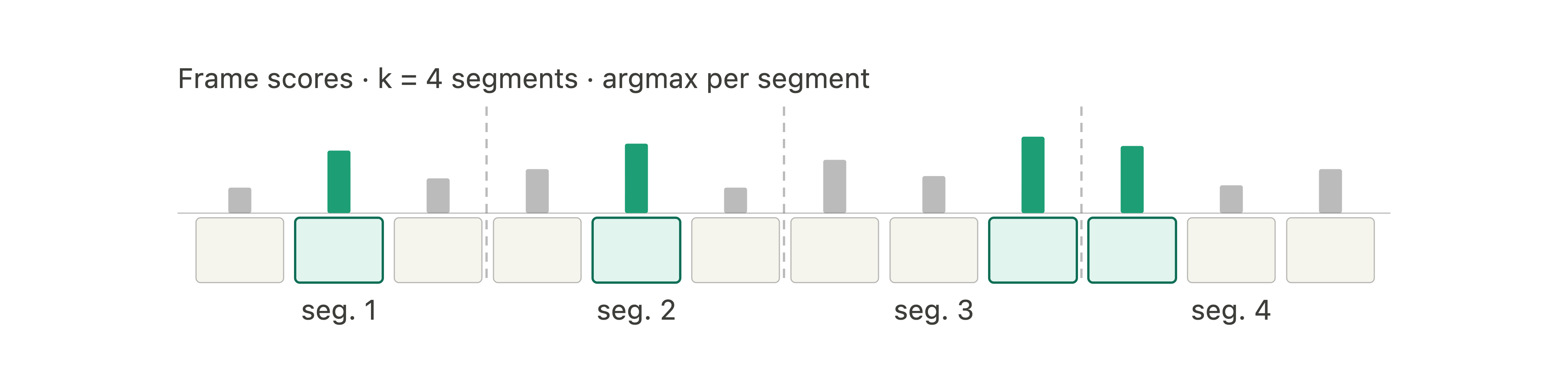
This policy combines two priors: the scorer chooses content-rich frames locally, while the segments preserve temporal coverage. For k = 1, stratified argmax reduces to selecting the single highest-scoring frame in the video. The selected frames are sorted in temporal order before being forwarded to the downstream captioning model.
Experiments
Data
We train our model on ActivityNet Captions, using the official splits and report all metrics on the test set. We also evaluate on the MSR-VTT test split without re-training to assess zero-shot transfer to clip-level captioning. Table 1 summarizes the splits used for training and evaluation.
Table 1: Statistics of the splits used for training and evaluation.
ActivityNet Captions
ActivityNet Captions (ANC) consists of untrimmed YouTube videos drawn from the ActivityNet dataset, each densely annotated with multiple temporally-localized natural language descriptions. A single video contains, on average, between 3 and 4 overlapping or sequential events, with a typical total duration of about two minutes. Every annotated event is described by a free-form English sentence.
MSR-VTT
MSR-VTT contains short web video clips paired with 20 crowd-sourced English captions per clip. Unlike ANC, captions describe the entire clip rather than localized events, so each test video contributes a single “segment” whose temporal extent coincides with the clip itself. We use MSR-VTT exclusively for evaluation, in order to probe whether our model trained on ANC videos generalizes zero-shot to clips with a different caption distribution.
Training and Evaluation
We train PEEK on the ANC dataset, and evaluate our trained selector on video captioning, on both ANC and MSR-VTT test sets, selecting 1, 2, 4 or 8 frames that are fed to a downstream VLM. We compare PEEK against five training-free frame selection methods:
- Oracle is the teacher model which has access to ground-truth captions. Although it cannot be used at inference time, we evaluate it to estimate an approximate upper bound on the sampler’s achievable performance.
- Uniform splits the (densely) sampled frames into k equal temporal sub-segments and selects the center frame of each.
- Random uses the same temporal sub-segments as Uniform and samples one frame at random from each sub-segment, using a fixed seed shared across all VLMs.
- MaxInfo selects a diverse, high-information subset by applying a maximum volume criterion to CLIP image embeddings; we use its fixed-cardinality mode with exactly k selected frames.
- CSTA is originally a video summarization method that predicts frame-importance scores and selects a summary under a length budget. Since our evaluation requires a fixed number of frames, we adapt only its scoring stage: frames are scored with CSTA, then one highest-scoring frame is selected from each of the k temporal sub-segments.
- PEEK is our student model trained on ANC with stratified argmax selection.
We fix the parameters and seed for all evaluated downstream VLMs for fair comparison, and use the same candidate frames for all methods.
For each selected frame budget, we generate captions conditioned only on the k chosen frames, in temporal order, and a short captioning prompt. We evaluate four downstream VLMs of various sizes: SmolVLM2-2.2B-Instruct, Qwen2.5-VL-3B, Qwen3.5-4B and Qwen2.5-VL-7B. We report CIDEr, which remains the primary metric for discussion because it is the most commonly reported metric for video captioning.
Results
ActivityNet Captions
Table 2: ActivityNet Captions test captioning metrics with different downstream VLMs and frame budgets. PEEK uses the same ActivityNet-trained checkpoint for all downstream VLMs. Oracle scores frames against the ground-truth caption.
Table 2 reports the results on ActivityNet Captions. The results show that PEEK is the strongest query-free selector on this benchmark, obtaining the best CIDEr in 14 out of 16 model/budget settings. The gains are most pronounced at k=1, where PEEK improves over the strongest query-free baseline by +1.74 CIDEr points for SmolVLM2-2.2B, +2.34 for Qwen2.5-VL-3B, +2.18 for Qwen3.5-4B, and +3.00 for Qwen2.5-VL-7B. The same conclusion holds at k=2, where PEEK is again best for all four VLMs, with gains ranging from+0.61 to +1.75 CIDEr points.
Compared with the adaptive baselines, PEEK is consistently stronger in the low-budget regime.
Zero-shot Transfer on MSR-VTT
Table 3: Zero-shot MSR-VTT test captioning metrics with different downstream VLMs and frame budgets. PEEK uses the same query-free ActivityNet-trained selector for all downstream VLMs. Oracle scores frames against the ground-truth caption.
Table 3 evaluates the same ActivityNet-trained selector on MSR-VTT, without re-training. This setting tests whether PEEK learns a transferable visual relevance prior rather than ANC specific domain distribution. The strongest transfer result is again obtained at k=1. PEEK is the best query-free method for all four downstream VLMs and all reported metrics in the one frame setting.
Efficiency
Table 4: Selection and end-to-end captioning time on the full ActivityNet Captions evaluation split with 17,505 segments, with SmolVLM2-2.2B-Instruct. Timings are measured on 4×NVIDIA A10G GPUs. We report total GPU time, with 4-GPU wall-clock estimates in parentheses. The full pipeline evaluates k ∈ {1, 2, 4, 8}.
Table 4 reports the selection and end-to-end captioning time on the full ANC evaluation split. Uniform and Random sampling have negligible selection cost, while all content-aware methods require an additional scoring pass over the candidate frames. On the ANC evaluation split, PEEK scores all 17,505 segments in 1h44m of GPU time, corresponding to 0.36s per segment. By contrast, CSTA requires 21h58m of GPU time, or 4.52s per segment, while MaxInfo requires 71h04m of GPU time, or 14.62s per segment. The Oracle is also more expensive than PEEK, requiring 9h52m of GPU time, or 2.03s per segment, and is not deployable because it uses the ground-truth caption.
When frame scores are reused for the full k ∈ {1, 2, 4, 8} captioning pipeline, PEEK increases total GPU time by only 5.2% over Uniform. In comparison, CSTA increases the total time by 65.4%, MaxInfo by 211.9%, and the Oracle by 29.4%. Thus, PEEK is not free, but it is a lot cheaper than the other content-aware selectors evaluated here. This efficiency is central to its practical value: PEEK recovers part of the Oracle’s caption-relevance signal while remaining query-free and lightweight enough to be used as a practical preprocessing stage.
Qualitative analysis

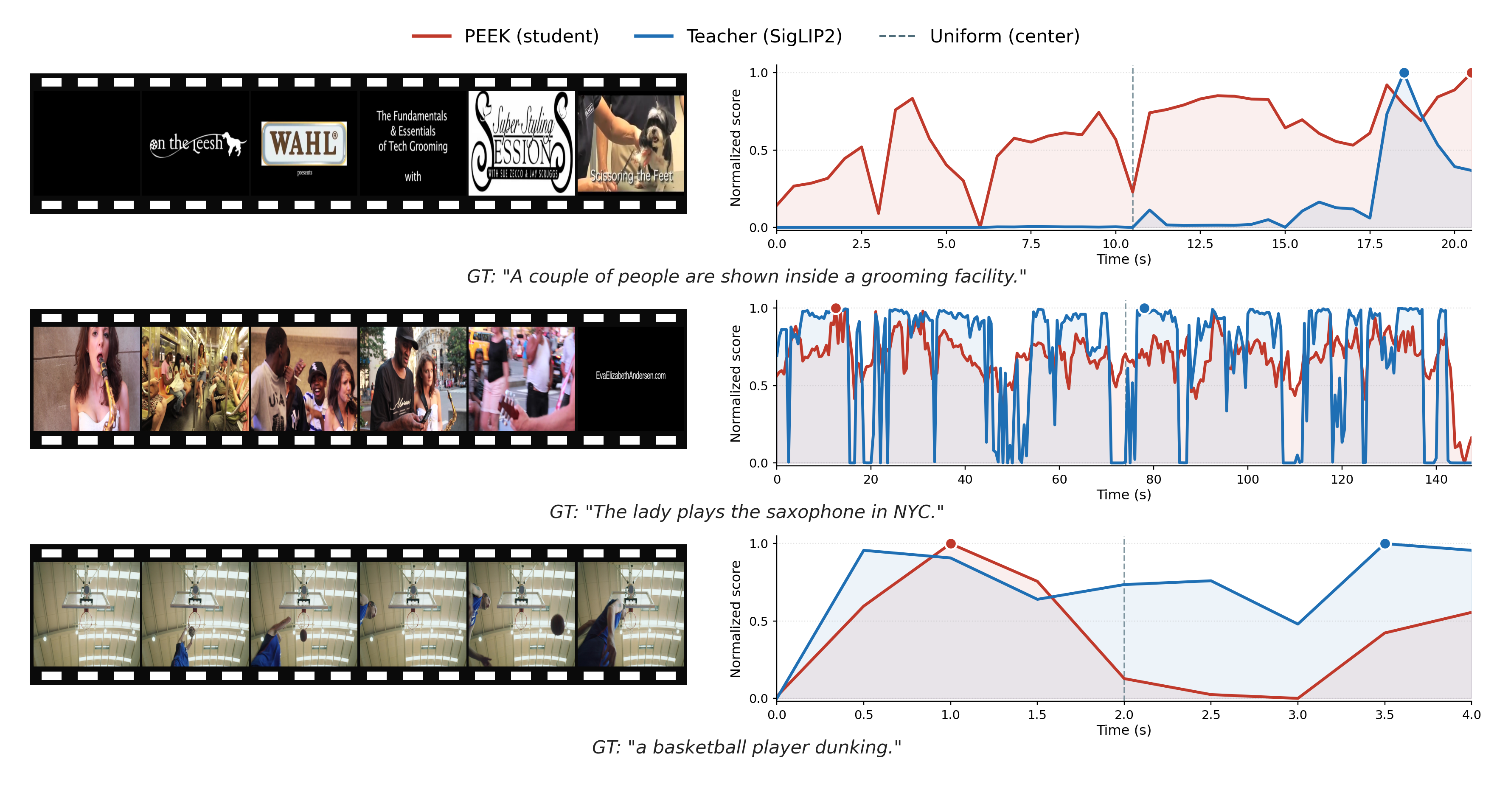
To complement the quantitative results, Figure 5 compares PEEK and SigLIP2 scores on ANC test segments. The two methods agree on global salient regions but often differ locally, with PEEK producing smoother temporal profiles than the frame-wise Oracle. Figure 4 shows PEEK strength: only PEEK identifies the player dunking, while uniform and the teacher both miss it.
Discussion and limitations
The results indicate that learned frame selection is most useful when the visual budget is tight. Across both benchmarks, PEEK is the best query-free selector in all one-frame CIDEr settings and in most two-frame settings. This supports the central hypothesis of the paper: part of the caption-conditioned relevance signal produced by an Oracle teacher can be recovered from visual evidence alone. The comparison with CSTA and MaxInfo shows that our method is different from generic video summarization, or visual diversity alone. Instead, PEEK learns a caption-oriented notion of visual relevance that is particularly useful when only one or two frames can be passed to the captioner.
At the same time, the results should not be interpreted as showing that learned frame selection is universally preferable to uniform sampling. Uniform remains a strong baseline, especially when several frames can be forwarded to the captioner. This is particularly visible on MSR-VTT at k=4, where Uniform often obtains the best CIDEr. The likely reason is the evaluation setting: ANC segments and MSR-VTT clips are relatively short, so a few uniformly spaced frames often cover the main event. As the frame budget increases, the value of selecting the single most relevant frame decreases, while temporal coverage and diversity become more important.
Another limitation is that the teacher signal is derived from ground-truth captions. This makes it useful as Oracle supervision, but it also ties the learned notion of relevance to reference-caption alignment rather than to all visually meaningful events in the video. A frame that supports a correct but non-reference caption may receive a weak teacher score. This limitation is also related to the use of reference-based captioning metrics, which can penalize correct captions that differ from the reference and can behave non-monotonically as more visual context is added. Extending this analysis to longer videos, adaptive frame budgets, and human or model-based factuality judgments would give a more complete picture of when learned frame selection is preferable.
A final limitation is that our evaluation is restricted to short-caption generation. Both ANC segments and MSR-VTT clips are associated with relatively compact descriptions, while long-form video captioning may require preserving multiple events, fine-grained temporal order, and details that are not all captured by a single caption-conditioned relevance ranking. In such settings, selecting only the most caption-aligned frames could overemphasize the dominant event and discard secondary but still important visual cues. Moreover, although PEEK is query-free by design, other video understanding tasks such as video question answering or retrieval may benefit from task- or query-specific frame selection. Our method could still be useful as a lightweight first-stage selector or as a transferable initialization, but evaluating this requires dedicated experiments. Extending the distillation framework to longer descriptions, adaptive frame budgets, and query-conditioned supervision is therefore an important direction for future work.
Conclusion
- We introduced PEEK, a state-of-the-art query-free frame selector for video captioning.
- PEEK also provides a favorable efficiency trade-off. It is much faster than CSTA and MaxInfo, while consistently outperforming them in the low-frame regime. This makes it a practical selector for efficient video captioning and a natural candidate for related applications such as thumbnail or preview-frame selection.
Paper: https://arxiv.org/abs/2605.31029
Project page: https://www.killian-steunou.com/peek/



